One a cold Tuesday in February, The Metropolitan Museum of Art quietly released data and images on it’s entire collection to the public. With over 200,000 pieces in it’s collection, The Met is the largest Museum in the Western Hemisphere, and contains relics from 3,800 B.C.
I’m a member of the Met, and try to visit ever 5-6 months. While I enjoy the experience, one concerning theme that I noticed with this dataset was the lack of data governance. While it’s understandable that certain pieces would be missing information due to age and lack of record keeping, I found lot’s of objects missing basic data. In some cases, when the person categorizing the data wasn’t sure, they added a “(?)” after the name.
Country of origin
79% of the pieces in the collection don’t have a country listed
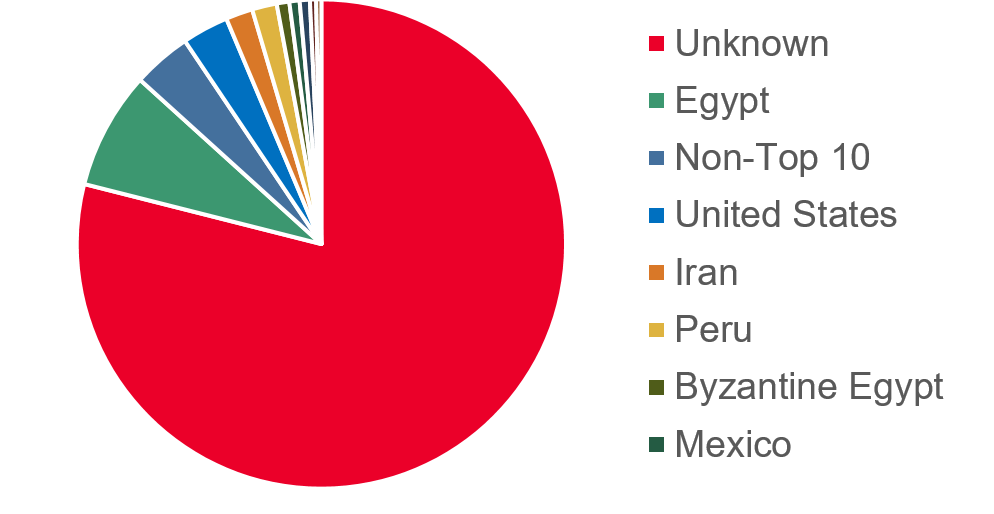
57% don’t have an artist name (not including objects attributed to anonymous)
10% don’t have a classification (ie: Print, Drawings, Ceramic)
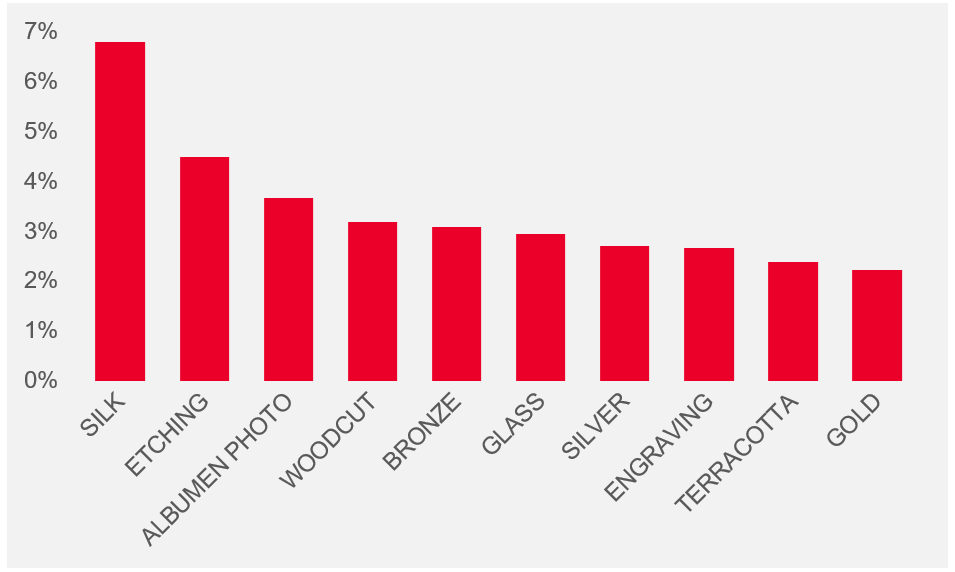
The Met has more than paintings
- 6.8% of pieces are silk
- 4.5% are etchings
- 3.7% are Photos
Top Artists at the Met
- 57% of pieces don’t have an artist listed
- 2,908 pieces from Allen & Ginter (mostly cards from a tobacco company)
- 314 Rembrandt
- 24 Van Gogh
- 23 Pollock
- 16 Michelangelo
Conclusion
When I heard that the Met had released it’s data to the public I was excited because I though this was an opportunity to find interesting facts and trends on the different pieces. What I found was missing datapoints, and inconsistent data that made the dataset difficult to navigate. I think my next option is to throw this into Python and clean up the data. I’ll continue to look into the data more and hopefully will have a better post in the future.
Data Sources:
The Metropolitan Museum of Art via Google Bigquery
Microsoft Excel for visualization
Become a Met Member